


Java IO
体系结构
IO实际上分为阻塞型IO(Blocking IO)和非阻塞型IO(Non-Blocking IO 简称NIO)
阻塞型IO在读取数据时,如果数据未到达,会一直阻塞直到读取到数据为止,所以称为阻塞型IO,在高并发的环境下性能不佳。
NIO不是使用 “流” 来作为数据的传输方式,而是使用通道,通道的数据传输是双向的,而且NIO的数据写入和读取都是异步的,能读/写多少就读/写多少,不会阻塞线程,所以称为非阻塞型IO,在高并发的环境下性能很好。
本章主要分析阻塞型IO
分门别类
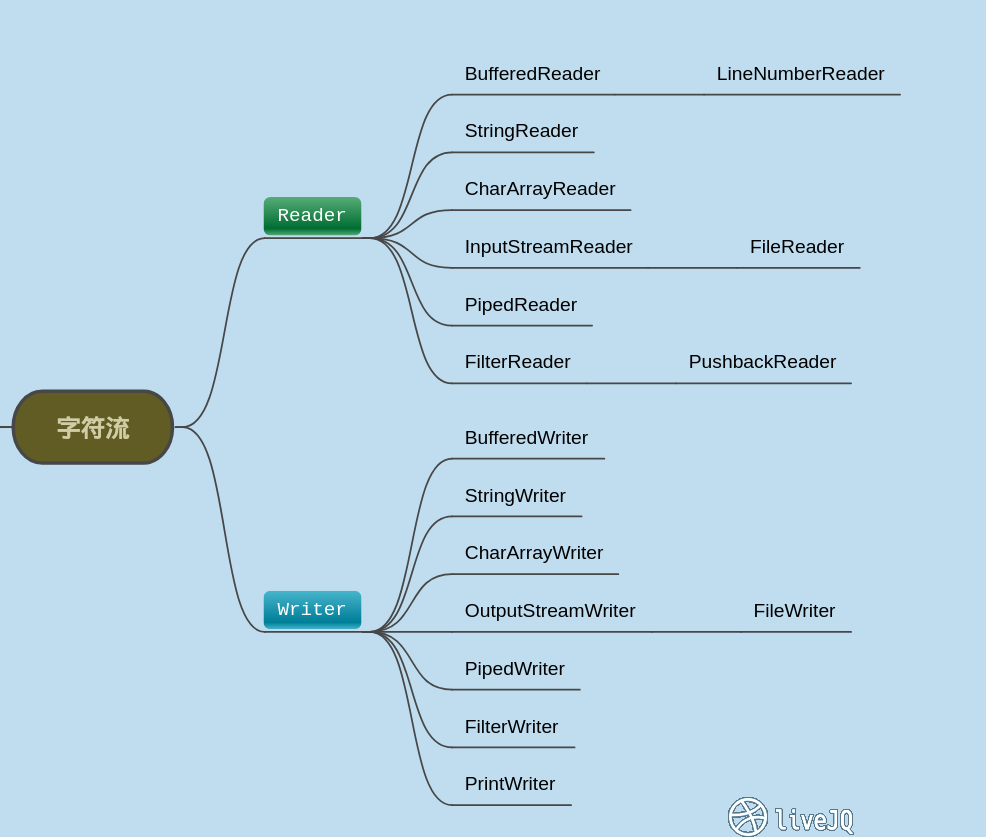
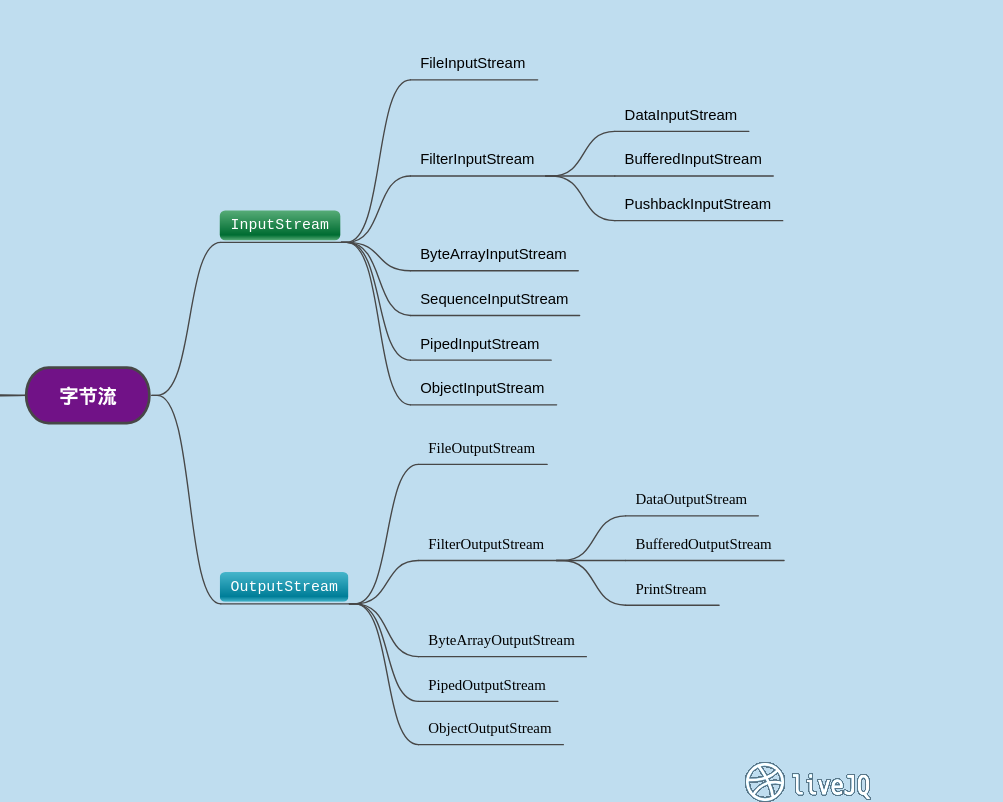
注意:在JDK8,InputStream淘汰了StringBufferInputStream和FilterInputStream中的LineNumberInputStream
- 按照数据流的方向不同可以分为:输入流和输出流。
- 按照处理数据单位不同可以分为:字节流和字符流。
- 按照实现功能不同可以分为:节点流和处理流。
- 输入输出是相对于“当前程序”来说的,输入要有“源”(本地文件/终端输入/网络传输 -> 程序),输出要有“目的地”(程序数据 -> 本地文件/终端输出/网络传输)。
- 字节流一次读取一个字节的数据,而字符流一次读取两个字节的数据。字符流实际上等于字节流+查询相应编码(UTF-8/GBK/gb2312等),主要是为了方便处理文字数据;而字节流可以处理任何数据(因为avi/mp4视频格式、png/jpg图片等都是转化为二进制存储在计算机中的)。
- 处理流是为了更好的处理节点流而存在的,例如功能介绍中的BufferedReader代码块:其中的InputStreamReader和BufferedReader就是处理流,而FileInputStream是节点流。“更好地处理”体现为:InputStreamReader是连接字节流和字符流的桥梁,采用UTF-8字符集将文件输入流中的字节转为字符;而BufferedReader可以形成缓冲区,一次性读取到缓冲区后再刷出,提高了处理效率,只是最后别忘了flush刷出缓存数据。
上面提到的代码块中值得注意的地方就是其关闭流的方式。一般我们常用的关闭流的方式:先打开的后关闭;而当存在处理流时,直接关闭最外层的处理流即可。由于装饰器模式的缘故,其内部的close方法直接将与其相关的流通通关闭掉了,需要注意的是,关闭流得包含在finally语句中,避免因发生异常而无法正常关闭资源。(若打开的资源较多时可以使用线程中的Hook来执行资源的回收任务,这里使用了JDK 7中提供的try-with-resources,本站有提供相关说明)。
功能展示
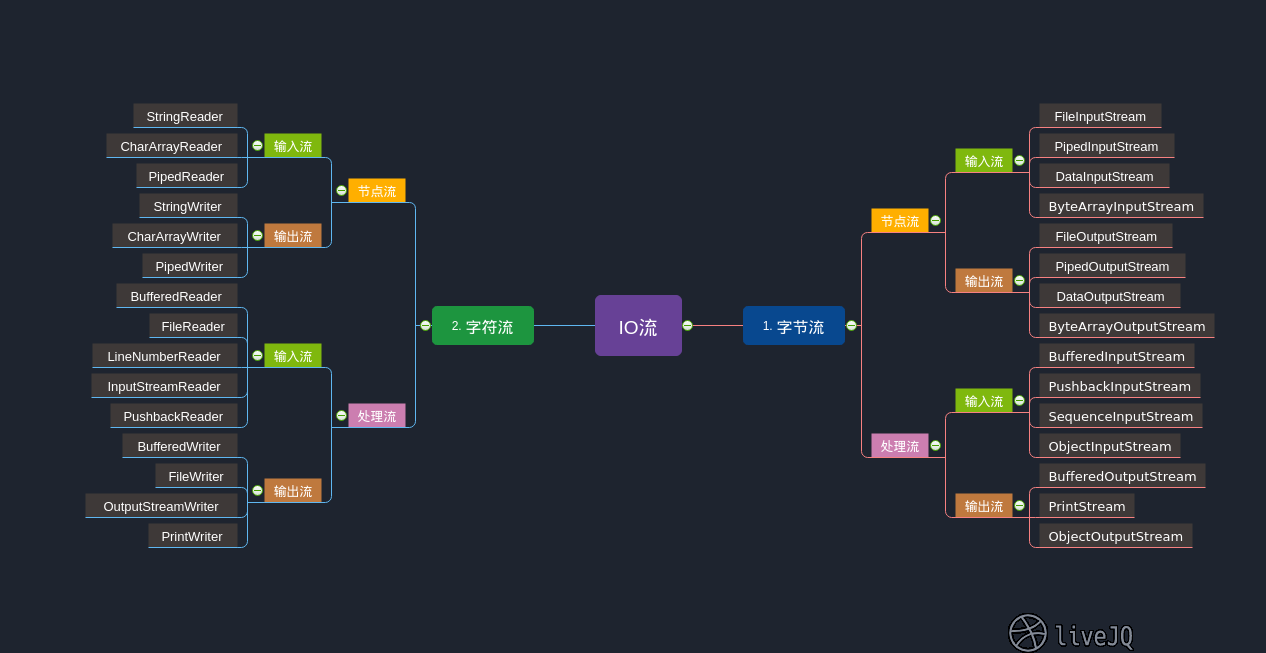
采用装饰器的基本上都是处理流了
字符流
BufferedReader
- 实例一:
File file = new File("README.md");
try (BufferedReader in =
new BufferedReader(
new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8))) {
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
// 与上面功能相同
File file = new File("README.md");
Charset charset = Charset.forName("utf8");
// 解码器
CharsetDecoder decoder = charset.newDecoder();
try (BufferedReader in =
new BufferedReader(new InputStreamReader(new FileInputStream(file), decoder))) {
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
这三个流经常这样搭配着使用。由上文所述,InputStreamReader是字节流到字符流的桥梁,那么OutputStreamWriter就是字符流到字节流的桥梁了,因用法相同,不再赘述。
BufferedWriter
- 实例一:
File file = new File("temp/test.txt");
try (BufferedWriter out =
new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(file), StandardCharsets.UTF_8))) {
int count = 10;
int index = 0;
while (++index != count) {
System.out.println("正在写入第 " + index + " 行");
out.write(index + " " + "测试行测试行.......");
out.newLine();
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
LineNumberReader
当传输的文本信息中包含某个错误时,向用户反馈错误时指出错误所在行号则更容易找到错误。
- 实例一:
try (LineNumberReader lineNumberReader =
new LineNumberReader(new FileReader("temp/test.txt"))) {
int data = lineNumberReader.read();
StringBuilder sb = new StringBuilder();
int index = -1;
while (data != -1) {
char dataChar = (char) data;
sb.append(dataChar);
// 从0开始,对应文件中的第1行
int tempIndex = lineNumberReader.getLineNumber();
if (index != tempIndex) {
System.out.println(tempIndex);
index = tempIndex;
}
data = lineNumberReader.read();
}
System.out.println(new String(sb));
} catch (IOException e) {
e.printStackTrace();
}
身为BufferedReader的子类,上面同样可以使用readLine()读取一整行数据。
- 实例二:
try (LineNumberReader lineNumberReader =
new LineNumberReader(new FileReader("temp/test.txt"))) {
String data = lineNumberReader.readLine();
StringBuilder sb = new StringBuilder();
while (data != null) {
sb.append(data).append(System.lineSeparator());
System.out.println(lineNumberReader.getLineNumber());
data = lineNumberReader.readLine();
}
System.out.println(sb);
} catch (IOException e) {
e.printStackTrace();
}
PrintWriter
- 实例一:
try (PrintWriter printWriter =
new PrintWriter(new FileWriter("temp/test.txt"))) {
printWriter.println(true);
printWriter.println(123);
printWriter.println((float) 123.456);
printWriter.printf(Locale.CHINA, "data: %d$", 123);
} catch (IOException e) {
e.printStackTrace();
}
文件内容:
true
123
123.456
data: 123$
PrintWriter其实也是Decorator,其中包含了BufferedWriter和OutputStreamWriter,若写出到文件,则还使用了FileOutputStream。除了集成上面这些类的功能外,其另一强大之处在于包含了许多format方法和printf,可以很容易地对数据进行格式化。
FileReader
- 实例一:
// 上面的 BufferedReader 实例可以简写成
File file = new File("README.md");
try (BufferedReader in = new BufferedReader(new FileReader(file))) {;
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
- 实例二:
FileReader fileReader = null;
try {
fileReader = new FileReader(new File("README.md"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
char[] destination = new char[1024];
int charsRead = 0;
try {
charsRead = fileReader.read(destination, 0, destination.length);
} catch (NullPointerException | IOException e) {
e.printStackTrace();
}
try {
while (charsRead != -1) {
System.out.println(new String(destination));
// 会尝试读取指定长度的字符数据到指定的字符数组中
// 如果文件中的字符数少于指定的字符数,则读取的字符数将少于指定的字符数
charsRead = fileReader.read(destination, 0, destination.length);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fileReader != null) {
try {
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
由上面可知,FileReader实际上是InputStreamReader与FileInputStream的组合。
StringReader
- 实例一:
String str = "中文";
try (StringReader stringReader = new StringReader(str)) {
int data = 0;
try {
// 一个字符一个字符的读取,也就是一次读取两个字节
data = stringReader.read();
} catch (IOException e) {
e.printStackTrace();
}
while (data != -1) {
char c = (char) data;
System.out.println("编码值:" + data + ", 字符:" + c);
try {
data = stringReader.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}
read()方法是其主要的功能,可以将字符串转为Reader来进行操作,这在需要传入Reader作为参数的组件时是非常有用的。这个实例将StringReader换成CharArrayReader时,只要将字符串转成char[]数组后传入一样运行;若换成FileReader,则将从字符串中读取的方式转成从文件中读取后一样运行。
- 实例二:
String str = "abcd";
char[] chars = new char[str.length()];
try (StringReader stringReader = new StringReader(str)) {
int num = 0;
int off = 0;
int len = 2;
try {
// 读取一部分字符到字符数组中
num = stringReader.read(chars, off, len);
} catch (IOException e) {
e.printStackTrace();
}
if (num != 0) {
System.out.println("字符:" + new String(chars, 0, num));
}
}
以上两个实例与CharArrayReader功能相同,直接替换即可,不再赘述。
CharArrayReader
- 实例一:
char[] chars = "abcd".toCharArray();
int data = 0;
int off = 0;
int len = 2;
try (CharArrayReader charArrayReader = new CharArrayReader(chars, off, len)) {
try {
data = charArrayReader.read();
} catch (IOException e) {
e.printStackTrace();
}
while (data != -1) {
char c = (char) data;
System.out.println("编码值:" + data + ", 字符:" + c);
try {
data = charArrayReader.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}
唯一与StringReader不同的就是CharArrayReader可以在构造方法中指定读取某段字符。
PushbackReader
- 实例一:
// 指定一次可以放回多少个char,默认为1个
int limit = 1;
try (PushbackReader pushbackReader =
new PushbackReader(new FileReader("temp/test.txt"), limit)) {
int data = pushbackReader.read();
if (data != -1) {
char dataChar = (char) data;
System.out.println("编码:" + data + ", 字符:" + dataChar);
}
pushbackReader.unread(data);
data = pushbackReader.read();
if (data != -1) {
char dataChar = (char) data;
System.out.println("编码:" + data + ", 字符:" + dataChar);
}
} catch (IOException e) {
e.printStackTrace();
}
由于读取字符数据后又将其放回,所以两次的输出结果是一样的。
编码:27979, 字符:测
编码:27979, 字符:测
关键SourceCode:
public int read() throws IOException {
synchronized (lock) {
ensureOpen();
if (pos < buf.length)
return buf[pos++];
else
return super.read();
}
}
public void unread(int c) throws IOException {
synchronized (lock) {
ensureOpen();
if (pos == 0)
throw new IOException("Pushback buffer overflow");
buf[--pos] = (char) c;
}
}
简单查看SourceCode可知,其读取字符数据时是先创建了指定大小的char[] buf数组,用来保存需要放回的字符(由limit参数指定大小),然后用一个int型pos变量记录与buf的相对位置(相同即表明并未放回任何数据)。当调用了unread方法时,先前所创建的char[] buf数组将用来保存指定的字符(读取出来的字符编码),回退字符顺序与保存的字符顺序一致。当再次read时,每次先进行判断,若pos与buf不等,则先从buf字符数组中读取。
字符流线程安全问题
/**
* The object used to synchronize operations on this stream. For
* efficiency, a character-stream object may use an object other than
* itself to protect critical sections. A subclass should therefore use
* the object in this field rather than <tt>this</tt> or a synchronized
* method.
*/
protected Object lock;
Reader 和 Writer 抽象类中定义的read和write方法中都有同步锁,所以都是线程安全的。默认使用对象本身进行初始化lock,但其表明为了使效果更好,可以使用需要同步的对象而非本身,然后子类沿用此lock。
Pipe
Java IO中的管道提供了在同一JVM中运行的两个线程进行通信的能力。因此,管道也可以是数据的来源或目的地。Java中的管道概念不同于Unix / Linux中的管道概念,其中在不同地址空间中运行的两个进程可以通过管道进行通信。在Java中,通信方必须在同一进程中运行,并且应该是不同的线程(在一个线程中调用下面两个对象容易发生deadlock!)。
- 实例一:
ThreadGroup group1 = new ThreadGroup("group1");
PipedOutputStream output = new PipedOutputStream();
try (PipedInputStream input = new PipedInputStream(output)) {
Thread thread1 =
new Thread(
group1,
() -> {
try {
output.write("Hello world, pipe!".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
});
Thread thread2 =
new Thread(
group1,
() -> {
try {
int data = input.read();
while (data != -1) {
System.out.print((char) data);
data = input.read();
}
} catch (IOException e) {
e.printStackTrace();
}
});
group1.setDaemon(true);
thread1.start();
thread2.start();
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException | IOException e) {
e.printStackTrace();
}
输出结果:
> Task :PipeDemo.main()
java.io.IOException: Write end dead
at java.io.PipedInputStream.read(PipedInputStream.java:310)
at bio.pipe.PipeDemo.lambda$main$1(PipeDemo.java:35)
at java.lang.Thread.run(Thread.java:748)
Hello world, pipe!
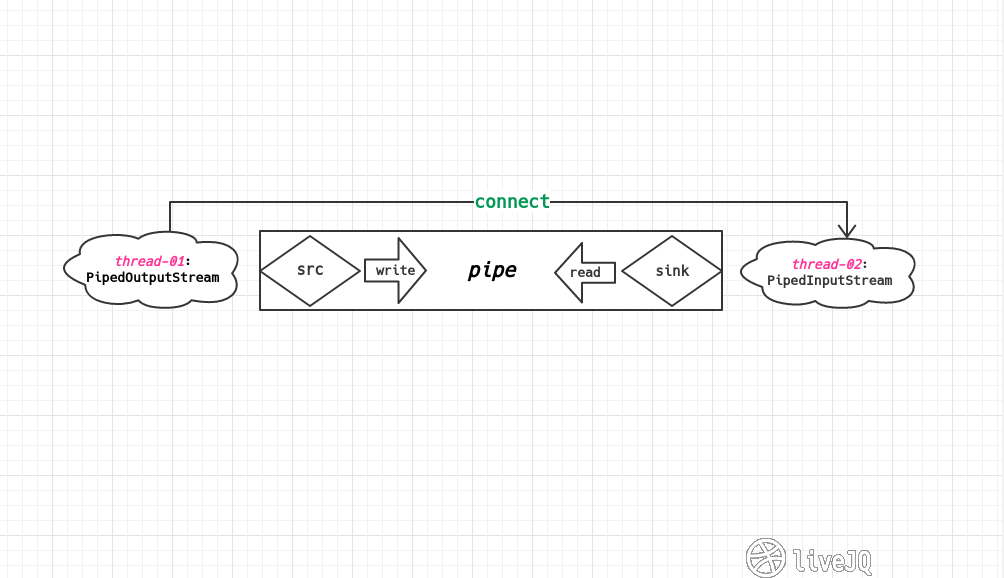
源码简单解读
- 实例化
// PipedInputStream中的connect方法还是调用了下面PipedOutputStream中的connect方法
public void connect(PipedOutputStream src) throws IOException {
src.connect(this);
}
// PipedOutputStream中的connect方法
public synchronized void connect(PipedInputStream snk) throws IOException {
if (snk == null) {
throw new NullPointerException();
} else if (sink != null || snk.connected) {
throw new IOException("Already connected");
}
// 持有PipedInputStream对象
sink = snk;
snk.in = -1;
snk.out = 0;
snk.connected = true;
}
在实例化的过程中,不管是在 PipedOutputStream 中传入 PipedInputStream,还是在 PipedInputStream 中传入 PipedOutputStream,最终都是调用 PipedOutputStream 中的 connect 方法来建立管道连接的。上面出现的in、out等变量挺重要的,有必要了解一下PipedInputStream在实例化的过程中初始化了一些变量:
// 一些状态标识,如:读/写是否关闭,连接是否创建
boolean closedByWriter = false;
volatile boolean closedByReader = false;
boolean connected = false;
// 这是标准配置,一写一读两个线程
Thread readSide;
Thread writeSide;
// 初始化读取数据后暂时保存的循环缓冲区大小
private static final int DEFAULT_PIPE_SIZE = 1024;
// 默认1024,可在构造函数的参数中设置以更改默认值
protected static final int PIPE_SIZE = DEFAULT_PIPE_SIZE;
// 读取数据后暂时保存的循环缓冲区
protected byte buffer[];
// 保存循环缓冲区中当前保存的位置,int<0代表空,int==out代表满
protected int in = -1;
// 保存循环缓冲区中将要保存的下一个空位置
protected int out = 0;
- 数据传输
// PipedOutputStream
public void write(int b) throws IOException {
if (sink == null) {
throw new IOException("Pipe not connected");
}
sink.receive(b);
}
// PipedInputStream
protected synchronized void receive(int b) throws IOException {
checkStateForReceive();
writeSide = Thread.currentThread();
if (in == out)
awaitSpace();
if (in < 0) {
in = 0;
out = 0;
}
buffer[in++] = (byte)(b & 0xFF);
if (in >= buffer.length) {
in = 0;
}
}
由上可知,PipedOutputStream中持有PipedInputStream对象,在调用write方法写入数据时其实就是调用PipedInputStream中的receive方法来接收数据的,所以可以知道为啥SourceCode中说道的”若PipedInputStream不存在了,则证明这个管道被破坏了“的意思了吧~
- 关闭管道
// PipedOutputStream
public void close() throws IOException {
if (sink != null) {
sink.receivedLast();
}
}
// PipedInputStream
synchronized void receivedLast() {
closedByWriter = true;
notifyAll();
}
public void close() throws IOException {
closedByReader = true;
synchronized (this) {
in = -1;
}
}
PipedOutputStream 调用close方法关闭时会将 PipedInputStream 中的closedByWriter标识为true且通知其它阻塞的读取线程继续读完写入的数据(这一功能和其flush方法相同)。PipedInputStream 关闭时同样将closedByReader标识为true,只不过他顺带清空了循环缓冲区中的数据。
PipedReader和PipedWriter亦是如此。
字节流
DataOutputStream
DataInputStream 和 DataOutputStream除了实现抽象类InputStream和OutputStream中基本的read(byte[])和write(int )抽象方法外,还实现了DataInput和DataOutput接口,他们的线程安全问题依赖于使用者本身。
主要功能是可以直接输入和输出Java原始数据类型(如:int、long、float、Double等)。文档翻译:使用修改后的UTF-8编码以与机器无关的方式将字符串写入基础输出流。
- 实例一:
try (DataOutputStream out = new DataOutputStream(new FileOutputStream("temp/test3.txt"));
DataInputStream in = new DataInputStream(new FileInputStream("temp/test3.txt"))) {
out.writeByte(123);
out.writeChar('a');
out.writeShort(123);
out.writeInt(123);
out.writeFloat(123.45F);
out.writeLong(999999999);
byte byte97 = in.readByte();
char chara = in.readChar();
short short97 = in.readShort();
int int123 = in.readInt();
float float12345 = in.readFloat();
long long999999999 = in.readLong();
System.out.println("byte97 = " + byte97);
System.out.println("chara = " + chara);
System.out.println("short97 = " + short97);
System.out.println("int123 = " + int123);
System.out.println("float12345 = " + float12345);
System.out.println("long999999999 = " + long999999999);
} catch (IOException e) {
e.printStackTrace();
}
输出:
byte97 = 123
chara = a
short97 = 123
int123 = 123
float12345 = 123.45
long999999999 = 999999999
DataOutputStream中调用的每个上述writeXX方法都会保存写出的字节数(DataInputStream没有提供),然后可以调用size()方法返回目前为止写出的总字节数(最大值为Integer.MAX_VALUE)。
/**
* The number of bytes written to the data output stream so far.
* If this counter overflows, it will be wrapped to Integer.MAX_VALUE.
*/
protected int written;
/**
* Increases the written counter by the specified value
* until it reaches Integer.MAX_VALUE.
*/
private void incCount(int value) {
int temp = written + value;
// 判断是否溢出
if (temp < 0) {
temp = Integer.MAX_VALUE;
}
written = temp;
}
/**
* Returns the current value of the counter <code>written</code>,
* the number of bytes written to this data output stream so far.
* If the counter overflows, it will be wrapped to Integer.MAX_VALUE.
*
* @return the value of the <code>written</code> field.
* @see java.io.DataOutputStream#written
*/
public final int size() {
return written;
}
test3.txt文件打开来是这样子的,并且提示编码错误:
{ a { {B��f ;���
这也说明了DataInputStream和DataOutputStream往往搭配着一起使用的缘故(只有它看得懂:T)
注意:DataOutputStream中writeUTF(String)方法较为特别,与此对应的为readUTF()。
- 实例二:
DataInputStream in = null;
try {
in = new DataInputStream(new FileInputStream("temp/test.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try (DataOutputStream out = new DataOutputStream(new FileOutputStream("temp/test2.txt"));
BufferedReader line =
new BufferedReader(new InputStreamReader(Objects.requireNonNull(in)))) {
String count;
while ((count = line.readLine()) != null) {
for (int i = 0; i < count.getBytes().length; i++) {
System.out.println(count.getBytes()[i]);
}
System.out.println("已读入字符:" + count);
System.out.println("已读入字节数:" + count.getBytes().length);
out.writeUTF(count);
System.out.println("已写出字节数 written:" + out.size());
System.out.println("=======================");
System.out.println("=======================");
}
} catch (IOException e) {
e.printStackTrace();
}
DataInputStream in2 = null;
try {
in2 = new DataInputStream(new FileInputStream("temp/test2.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try (BufferedReader line2 =
new BufferedReader(new InputStreamReader(Objects.requireNonNull(in2)))) {
String count2;
while ((count2 = line2.readLine()) != null) {
for (int i = 0; i < count2.getBytes().length; i++) {
System.out.println(count2.getBytes()[i]);
}
System.out.println("已读入字字符:" + count2);
System.out.println("已读入字节数:" + count2.getBytes().length);
}
} catch (IOException e) {
e.printStackTrace();
}
英文测试
读取的test.txt文件:
a
b
输出:
97
已读入字符:a
已读入字节数:1
已写出字节数 written:3
=======================
=======================
98
已读入字符:b
已读入字节数:1
已写出字节数 written:6
=======================
=======================
0
1
97
0
1
98
已读入字字符: [][]a[][]b
已读入字节数:6
写出的test2.txt文件内容:
[]a[]b
// 原版doc说明
* Writes a string to the specified DataOutput using
* <a href="DataInput.html#modified-utf-8">modified UTF-8</a>
* encoding in a machine-independent manner.
* <p>
* First, two bytes are written to out as if by the <code>writeShort</code>
* method giving the number of bytes to follow. This value is the number of
* bytes actually written out, not the length of the string. Following the
* length, each character of the string is output, in sequence, using the
* modified UTF-8 encoding for the character. If no exception is thrown, the
* counter <code>written</code> is incremented by the total number of
* bytes written to the output stream. This will be at least two
* plus the length of <code>str</code>, and at most two plus
* thrice the length of <code>str</code>.
// 中文翻译
首先,将两个字节写入输出流,就像通过writeShort给出要遵循的字节数的方法一样。该值是实际写出的字节数,而不是字符串的长度。在该长度之后,使用针对该字符的修改的UTF-8编码依次输出该字符串的每个字符。如果没有抛出异常,则计数器written将增加写入输出流的总字节数。这将是至少两个加上长度`str`,并且最多两倍加三倍的长度str
输出结果结合文档可以知道,每次将读取到的字符通过writeUTF(String)输出时其前面都会带有两个字节的奇怪数据。01为十六进制,转为二进制,一位表示2的4次方,所以为一个字节,然后在方法中像writeShort()方法中那样进行了无符号右移操作>>> 8,所以总的用了两个字节进行存储,细节暂不深究。
中文测试
读取的test.txt文件:
中
b
输出:
-28
-72
-83
已读入字符:中
已读入字节数:3
已写出字节数 written:5
=======================
=======================
98
已读入字符:b
已读入字节数:1
已写出字节数 written:8
=======================
=======================
0
3
-28
-72
-83
0
1
98
已读入字字符: [][]中 [][]b
已读入字节数:8
猜想:01后面跟着的是占一个字节的字符,03后面跟着的是占三个字节的字符。
扩展
占2个字节的:带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码
占3个字节的:基本等同于GBK,含21000多个汉字
占4个字节的:中日韩超大字符集里面的汉字,有5万多个
一个utf8数字占1个字节
一个utf8英文字母占1个字节
少数是汉字每个占用3个字节,多数占用4个字节。
ByteArrayOutputStream
OutputStream中有一个需要传入byte数组的方法来写出数据:
public void write(byte b[]) throws IOException {
write(b, 0, b.length);
}
如果我们的数据是一个一个int型的,那么用ByteArrayOutputStream就可以很简单地将一个一个int数据集中到一个数组中去,然后很方便的调用上面这个方法写出。
实例一:
// 未指定初始化buf大小,则默认创建一个 buf[32] 大小的数组存储空间
try (ByteArrayOutputStream output = new ByteArrayOutputStream();
DataOutputStream dataOutput =
new DataOutputStream(new FileOutputStream("temp/test3.txt"))) {
output.write(97);
output.write(65);
System.out.println("buf 数组目前存储的数据大小:" + output.size() + " 个字节");
byte[] bytes = output.toByteArray();
dataOutput.write(bytes);
System.out.println("write successfully!");
} catch (IOException e) {
e.printStackTrace();
}
test3.txt文件:
aA
输出:
buf 数组目前存储的数据大小:2 个字节
write successfully!
其中需要注意的就是溢出问题
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
扩展:来自StackOverflow中的解释
数组对象的形状和结构(例如int值数组)类似于标准Java对象的形状和结构。主要区别在于数组对象有一段额外的元数据,表示数组的大小。然后,数组对象的元数据包括:类:指向类信息的指针,它描述对象类型。对于int字段数组,这是一个指向int []类的指针。
标志:描述对象状态的标志集合,包括对象的哈希码(如果有),以及对象的形状(即对象是否为数组)。
锁定:对象的同步信息 - 即对象当前是否已同步。
大小:数组的大小。
最大尺寸
2^31 = 2,147,483,648
作为数组,它自己需要8 bytes存储大小 2,147,483,648
所以
2^31 -8 (for storing size ),
所以最大数组大小定义为Integer.MAX_VALUE - 8
所以,那减去的8个字节是用来存储数组所需的各种元数据的。
private void ensureCapacity(int minCapacity) {
// overflow-conscious code
if (minCapacity - buf.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = buf.length;
int newCapacity = oldCapacity << 1;
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
buf = Arrays.copyOf(buf, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
newCapacity -> 即将增加后的数组大小
minCapacity -> 当前写入一个字节后的大小
每次写到buf中时都会调用 ensureCapacity 方法检查写出后的大小,若溢出,则将buf数组扩大10倍;若此扩大10倍后的数组大小溢出了(int型数据变成了负数),则直接等于刚才写入一个字节数据后的数组大小(也就是不一下子增很大,而是写一个增大一个);若超过 Integer.MAX_VALUE - 8 时,直接将buf增至Integer.MAX_VALUE,但这样的话就将元数据覆盖了呀,暂时不清楚为何要这样做:(
SequenceInputStream
实例一:
try (InputStream input1 = new FileInputStream("temp/test.txt");
InputStream input2 = new FileInputStream("temp/test2.txt")) {
SequenceInputStream sequenceInputStream = new SequenceInputStream(input1, input2);
int data = sequenceInputStream.read();
while (data != -1) {
System.out.println(data);
data = sequenceInputStream.read();
}
} catch (IOException e) {
e.printStackTrace();
}
test.txt:
ab
test2.txt:
cd
输出:
97
98
99
100
ObjectOutputStream
实例一:
/**
* 序列化就是将一个对象转换成字节序列,方便存储和传输。
* 序列化:ObjectOutputStream.writeObject()
* 反序列化:ObjectInputStream.readObject()
*/
public class SerializableDemo {
public static void main(String[] args) {
String objectFile = "test4.txt";
// 序列化
serialize(objectFile);
// 反序列化
deserialize(objectFile);
}
// 序列化
public static void serialize(String objectFile) {
A a = new A(1, "aaa");
try (ObjectOutputStream objectOutputStream =
new ObjectOutputStream(new FileOutputStream(objectFile))) {
objectOutputStream.writeObject(a);
} catch (IOException e) {
e.printStackTrace();
}
}
// 反序列化
public static void deserialize(String objectFile) {
try (ObjectInputStream objectInputStream =
new ObjectInputStream(new FileInputStream(objectFile))) {
A a2 = (A) objectInputStream.readObject();
System.out.println(a2);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
private static class A implements Serializable {
private int x;
// transient关键字声明不需要序列化的属性
private transient String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
}
输出:
x = 1 y = null
test4.txt文件:
��[]sr[]bio.bytes.SerializableDemo$AN��xY���[]I[]xxp []
字节流线程安全问题
两个抽象类中只有InputStream中的reset()和mark(int)方法存在synchronized,所以线程安全基本依赖于他们的子类。
扩展
Guava IO
难免错漏,敬请指正 :T

评论区