


Web API是网站的一部分,用于与使用非常具体的URL请求特定信息的程序交互。这种请求称为API调用。请求的数据将以易于处理的格式(如JSON或CSV)返回。依赖于外部数
据源的大多数应用程序都依赖于API调用,如集成社交媒体网站的应用程序。
因此,我们可以写一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
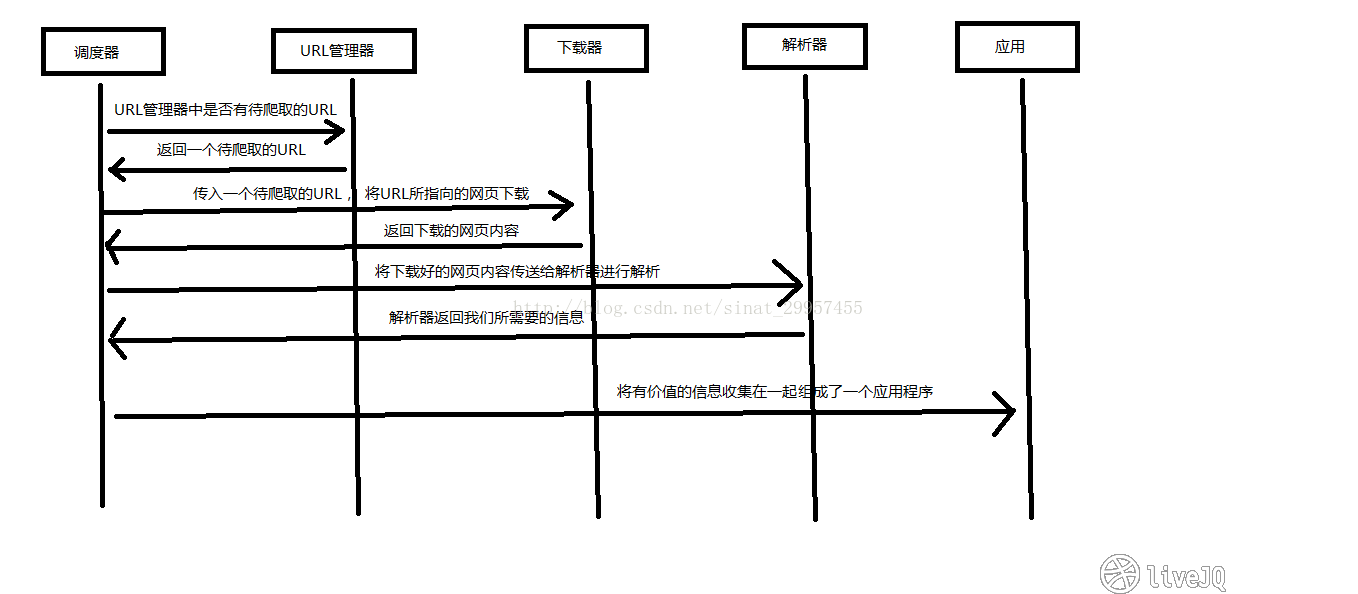
Python爬虫架构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
-
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
-
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
-
网页下载器:通过传入一个URL地址来下载网页,将网页转换成字符串或字节来处理。常用的下载器有urllib(Python官方基础模块)和requests(第三方模块)。
-
网页解析器:将得到的网页数据(字符串或字节类型)进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带)、bs4.BeautifulSoup(第三方),lxml.etree和lxml.html(第三方,可以解析 xml 和 HTML)。html.parser 和 BeautifulSoup 以及 lxml 都是以 DOM 树的方式进行解析的。
-
应用程序:就是从网页中提取的有用数据组成的一个应用。
调用下载器
现在一般都用第三方的模块,效率比较高。
requests
import requests
url = 'https://pkgstore.datahub.io/core/population/population_json/data/43d34c2353cbd16a0aa8cadfb193af05/population_json.json' # 获取json格式的数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36",
"Referer": "https://datahub.io/core/population"
}
response = requests.get(url, headers=headers)
print("Status Code: ", response.status_code) # 若成功则返回200请求码
wp_data = response.text
with open('world_population.json', 'w') as f:
f.write(wp_data)
headers=headers目的是为了模拟浏览器进行访问,这是最简单的反爬机制,如果对方提供此API,也可不写。
response.text返回的是字符串数据,所以下面可以用'w'方式,若为response.content则返回的是字节数据bytes,下面应该用'wb'方式,若有必要,还得提供encoding编码方式。
urllib
try:
from urllib2 import urlopen # python2.x
except ImportError:
from urllib.request import urlopen # python3.x
doubanUrl = 'https://movie.douban.com/top250?start=0&filter='
response = urlopen(doubanUrl)
status_code = response.getcode()
html = response.read()
print(status_code, html)
解析器解析数据
对获取到的网页数据进行解析,来获取我们想要的特定部分的内容
lxml.etree
lxml.etree尝试在任何地方都遵循ElementTree API,但是有一些不兼容性。
from lxml import etree
html = etree.HTML(source)
result = etree.tostring(html, pretty_print=True, method="html")
print(result)
allMovie = html.xpath('//div[@class="info"]')
from io import StringIO
from lxml import etree
broken_html = "<html><head><title>test<body><h1>page title</h3>"
parser = etree.HTMLParser()
tree = etree.parse(StringIO(broken_html), parser)
result = etree.tostring(tree.getroot(),pretty_print=True, method="html")
print(result)
#输出
b'<html>\n<head><title>test</title></head>\n<body><h1>page title</h1></body>\n</html>\n'
XML禁止在注释中使用双连字符,HTML解析器将很乐意在恢复模式下接受这些连字符。因此,如果您的目标是在解析后将HTML文档序列化为XML / XHTML文档,则可能必须首先应用一些手动预处理。
请注意,etree.HTML解析器旨在解析HTML文档。对于XHTML文档,请使用可识别名称空间的XML解析器。
lxml.html
从版本2.0开始,lxml附带了一个用于处理HTML的专用Python包:lxml.html。它基于lxml的HTML解析器,但为HTML元素提供了一个特殊的Element API,以及一些用于常见HTML处理任务的实用程序。
from lxml import html
content = html.document_fromstring(source)
allMovie = content.xpath('//div[@class="info"]')
解析给定字符串中的文档。这总是创建一个正确的HTML文档,这意味着父节点是,并且有一个正文,可能还有一个头。
BeautifulSoup
BeautifulSoup的一个非常好的功能是它对编码检测的出色支持,它可以为没有(正确)声明其编码的真实HTML页面提供更好的结果。
lxml通过lxml.html.soupparser 模块与BeautifulSoup接口。它提供了三个主要功能:fromstring()和parse() 使用BeautifulSoup将字符串或文件解析为lxml.html 文档,并使用convert_tree()将现有的BeautifulSoup树转换为顶级元素列表。
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#获取所有的链接
links = soup.find_all('a')
print("逐条链接的详细属性")
for link in links:
print(link.name,link['href'],link.get_text())
print("获取特定的URL地址")
link_node = soup.find('a',href="http://example.com/elsie")
print(link_node.name,link_node['href'],link_node['class'],link_node.get_text())
print("正则表达式匹配")
link_node = soup.find('a',href=re.compile("ti"))
print(link_node.name,link_node['href'],link_node['class'],link_node.get_text())
print("获取P段落的文字")
p_node = soup.find('p',class_='story')
print(p_node.name,p_node['class'],p_node.get_text())
#输出:
#逐条链接的详细属性
#a http://example.com/elsie Elsie
#a http://example.com/lacie Lacie
#a http://example.com/tillie Tillie
#获取特定的URL地址
#a http://example.com/elsie ['sister'] Elsie
#正则表达式匹配
#a http://example.com/tillie ['sister'] Tillie
#获取P段落的文字
#p ['story'] Once upon a time there were three #little sisters; and their names were
#Elsie,
#Lacie and
#Tillie;
#and they lived at the bottom of a well.

评论区