


第三版 PPT 开发文档
判题基本架构介绍
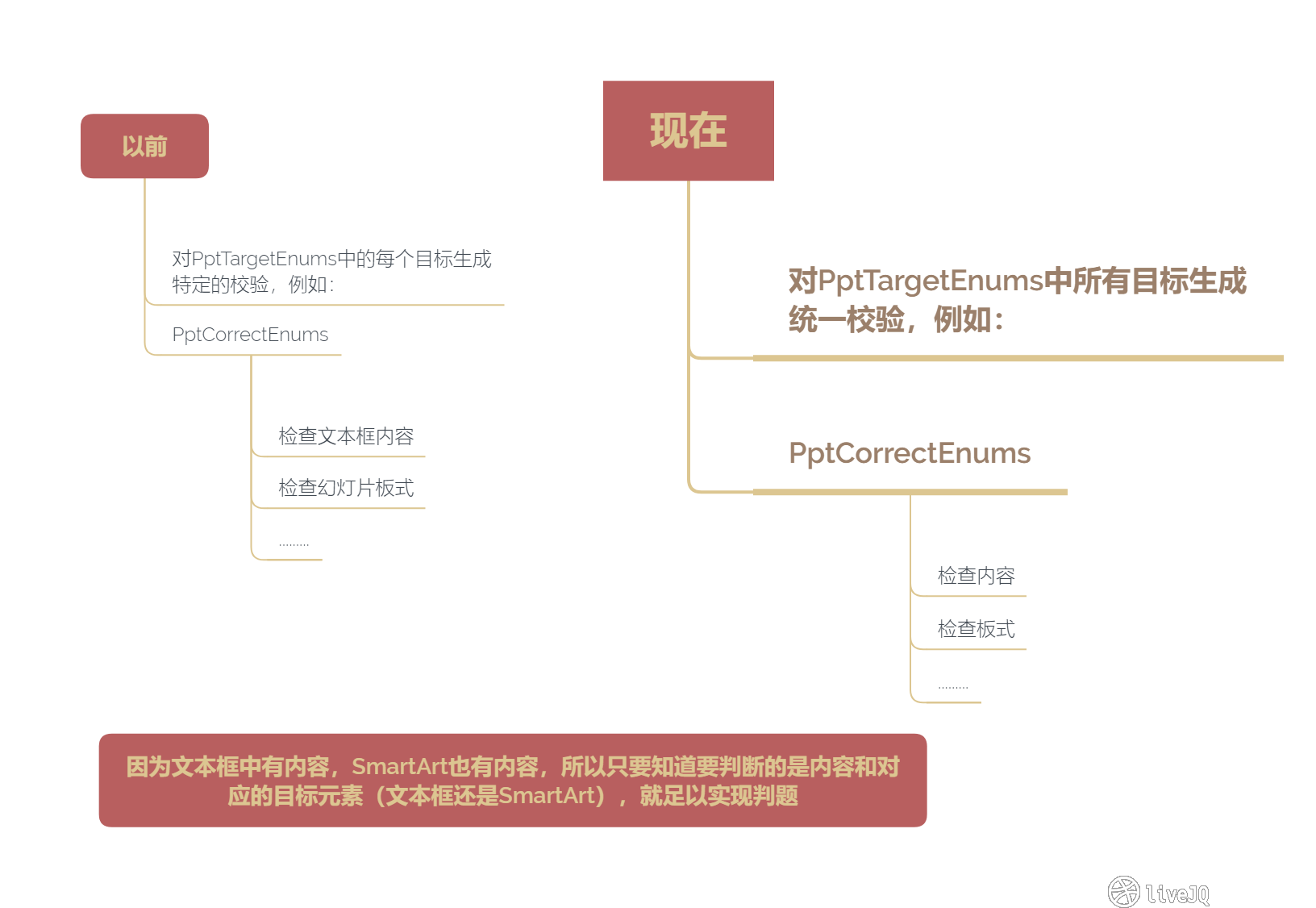
规则架构
PptValidationEntity
实体类,封装一整套试题,里面包含多个 PptElementValidationEntity
PptElementValidationEntity
实体类,封装试题中出现的每一道小题
- includeParamJson
json格式字符串,里面的参数所对应值只要匹配就得分 - excludeParamJson
json格式字符串,里面的参数所对应值只要不匹配就得分 - targetVerify
要判断的目标元素,封装在PptTargetEnums枚举类中 - slideIndex
要判断的是第几张幻灯片,跟数组一样,从0开始(输出时给人看的通常加上1)
Json格式
{
"id":"D34",
"fileName":"PPT.pptx",
"pptElementValidationEntities":[
{
"id":"01",
"score":"3.0f",
"targetVerify":"SMART_ART",
"includeParamJson":{
"TEXT_CONTENT":"会员代表大会会长理事会常务理事会秘书长秘书处办事机构咨询机构办公室业务准则和发展委员会业务准则部信息工作部党委工作部会员管理部教育培训部宣传编辑部奖惩维权委员会信息化建设委员会教育培训委员会资本市场委员会宣传委员会",
"FORMAT":{
"hierarchy":"1000",
"convert":"6000"
}
},
"excludeParamJson":{
"STYLE":{
"simple":"10100"
},
"COLOR":{
"accent1":"11200"
}
},
"slideIndex":"3"
}
]
}
返回结果架构
CheckInfoResult
保存判题结果类(包括正确、错误、异常,用枚举类 CheckStatus 封装),并附带message说明。其中包含的静态方法用于直接封装并返回此对象
过程架构
EnumUtils
工具类,可以通过 code、name 或 desc 来获取对应的枚举 enum
ParamMatchEnum
枚举类,用以分别走两种判题模式,是"匹配参数模式"还是"排除参数模式",并且可以保存在 CheckInfoResult 的输出结果信息中
PowerPointConstants
保存了一系列解析时要用到的简单常量(可以叫做解析标识符),这些标识符存在于 xml 中标明了特定的信息,以后可以不断增加,也可以统一修改成枚举类。
PptCorrectServiceImplTest
判题流程测试,用到了 PptTargetEnums 和 PptCorrectEnums 这两个枚举类,还有 PptUtils 工具类
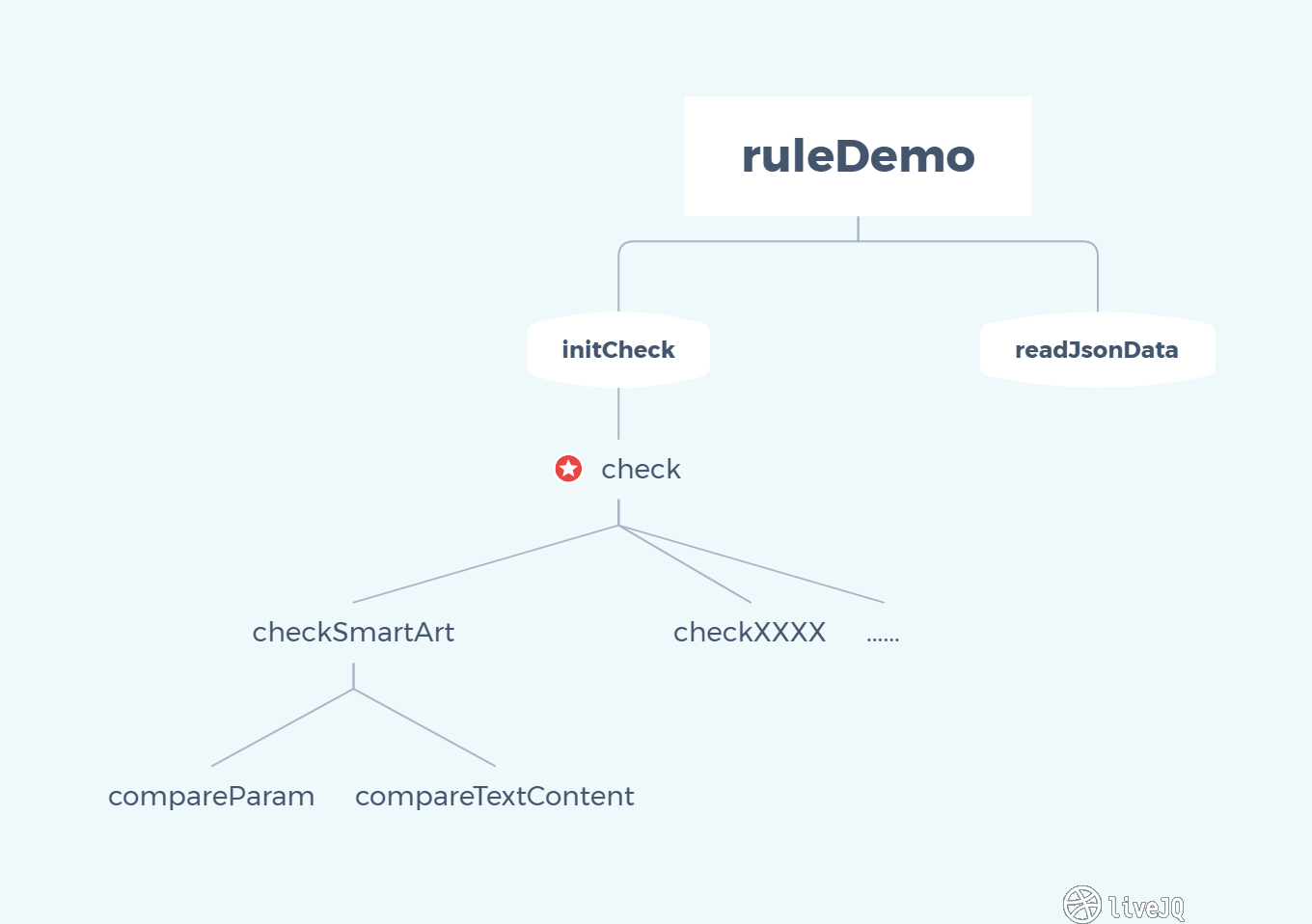
readJsonData 方法是为了测试而写的临时方法,读取本地规则。
由上图可以知道,后面的工作都是不断向 PptCheckUtils 补充 checkXXXX,测试类中的一些方法也应该加入到对应的工具类中,以形成规范系统的框架
判题过程总的可以分成三个部分:
- 获取资源:考生文件路径(外部传入) + 数据库中的规则(内部获取),而规则需要先封装到 PptValidationEntity 中。
- 开始判题:根据封装好的规则,循环检查每个 PptElementValidationEntity 中的 target 和 knowledge ,根据它们选择对应的方法来解析考生文件,将解析到的内容与规则对比得出结果。
- 收集结果信息:将每次的判题结果逐一收集,最后返回。
解析方法架构
主要写在 PptUtils 中,而 PptCheckUtils 则结合其中的一些方法,再加上一些判题过程生成某个 target 对应的判断方法,方法名都以check开头。
解析出演示文稿中的某个信息需要理解 POI 工具包处理的整个过程(注意:以下都是基于 pptx 后缀文件的解析方法,ppt后缀文件不完全适用)
创建PPT对象
/** 创建PPT对象 */
private XMLSlideShow slideShow;
slideShow = new XMLSlideShow(new FileInputStream(fileName));
创建成功后,slideShow 可以直接调用一些方法获取 PPT 文件的基本信息了,像文件里的幻灯片数量和主题、文件创建时间、最后一次修改时间等等。
获取幻灯片对象
// 所有幻灯片都在一个 List<XSLFSlide> 集合中
int num = 0;
for(XSLFSlide slide : ppt.getSlides()) {
slide = ppt.getSlides().get(num++);
}
方式一:直接通过 get 方法
解决 target:幻灯片主题等。
slide 就是一个幻灯片对象,通过它可以直接获取到一些属性,但条件非常苛刻。不仅需要满足基本的参数需要,还非常容易出现 NullPointException 的异常,更要命的是在后期获取信息时,很大一部分还获取不到😖
方式二:解析 xmlText
解决 target:文本框、图片、幻灯片切换方式、动画、嵌入式Doc等。
就在这个时候,出现了一个叫做 xmlText 文本信息,其中包含了幻灯片页面中所有基本元素信息。
System.out.println(slide.getXmlObject().xmlText());
下面就开始通过解析 xmlText 来判断文本框的对齐方式
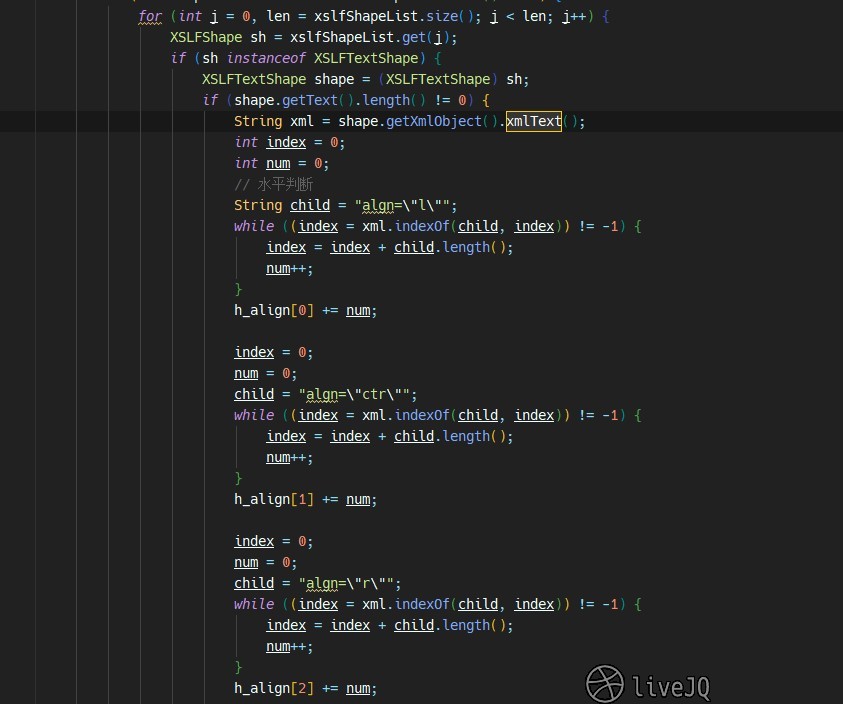
解析详情见开始接手工作的第三步
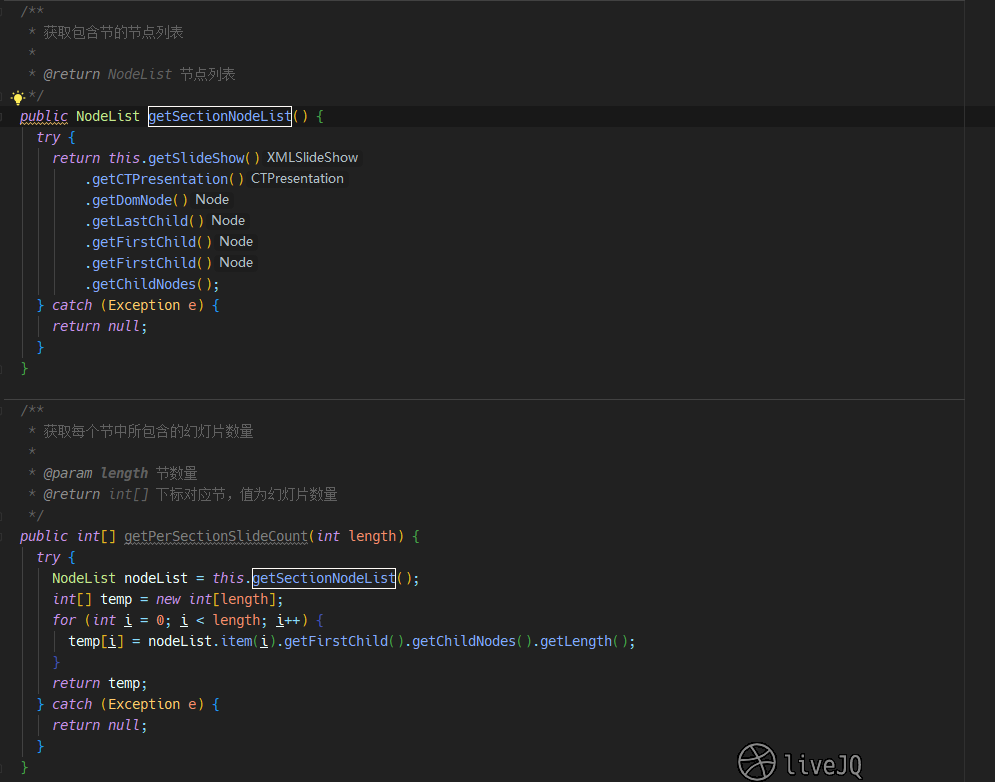
方式三:从 CTPresentation 获取 NodeList 中包含的信息
解决 target:节。
方式四:深入解析 XmlObject
解决 target:SmartArt、形状、视频、声音等。
/**
* 获取单个幻灯片中SmartArt元素的总拼接文本内容
*
* @param slide 所需获取文本内容的幻灯片对象
* @return java.lang.String
*/
public String getSmartArtSpliceText(XSLFSlide slide) throws IOException, XmlException {
StringBuffer stringBuffer = new StringBuffer();
XmlObject xmlObject;
XmlCursor xmlCursor;
for (POIXMLDocumentPart part : slide.getRelations()) {
if (part.getPackagePart()
.getPartName()
.getName()
.startsWith(PowerPointConstants.SMART_ART_DATA_RESOURCE_URL_PREFIX)) {
xmlObject = XmlObject.Factory.parse(part.getPackagePart().getInputStream());
xmlCursor = xmlObject.newCursor();
while (xmlCursor.hasNextToken()) {
if (xmlCursor.isText()) {
stringBuffer.append(xmlCursor.getTextValue());
}
xmlCursor.toNextToken();
}
}
}
return String.valueOf(stringBuffer);
}
POIXMLDocumentPart 链接着很多额外的元素信息,而这些信息都有各自对应的 uri 来标识,其中还蕴藏着很多未知的奥妙,留给你们一步一步探究下去吧~
开始接手工作
第一步
依照接口 CommonEnum,统一属性名和方法名
/** 属性编码Code */
private final Integer code;
/** 检查方法名称 */
private final String name;
/** 检索信息 */
private final String desc;
@Override
public Integer getCode() {
return code;
}
@Override
public String getName() {
return name;
}
@Override
public String getDesc() {
return desc;
}
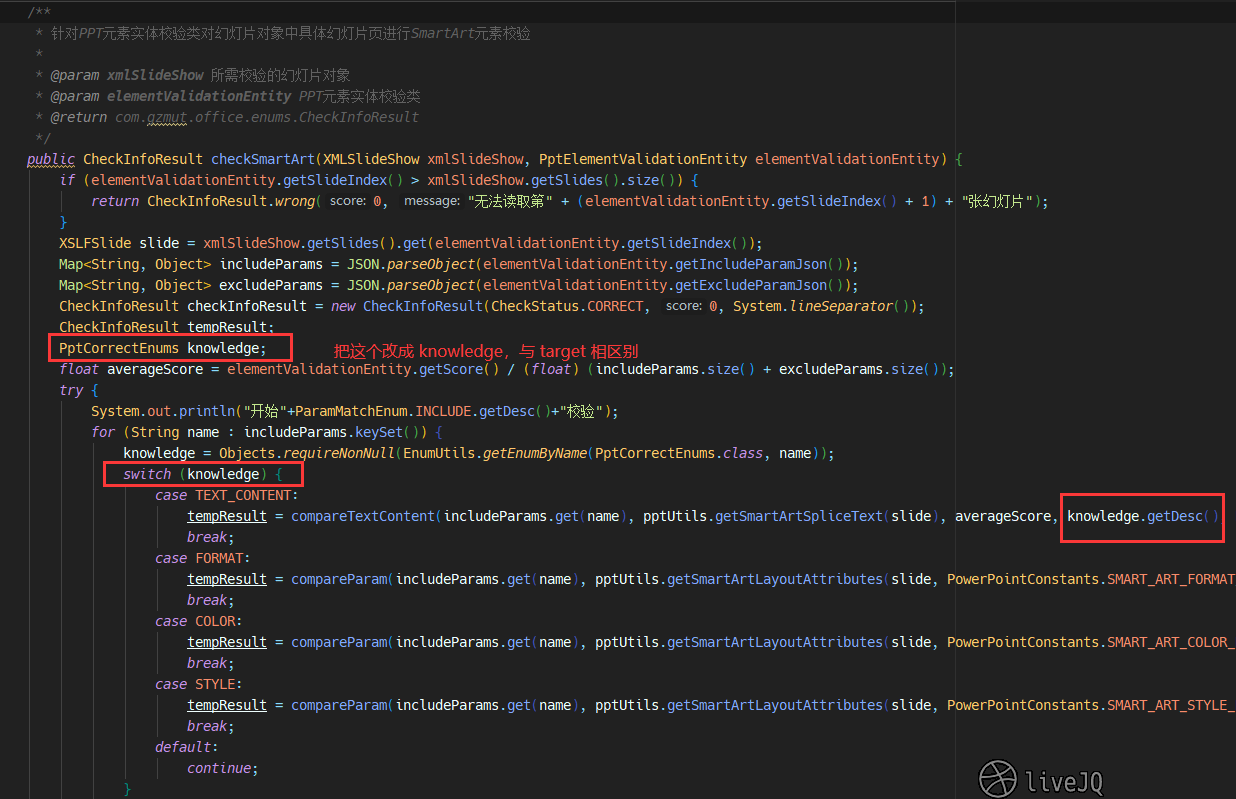
第二步
简化 PptCorrectEnums
Therefore,需要慢慢修改 PptCorrectEnums,以形成统一、简洁和完备的判题依据。而其它依据目标元素而写的枚举类 PptXXXXPropertiesEnums,则可以暂时当做参考,当 PptCorrectEnums 写完备后可以考虑将其删除。
封装成对象
将解析文档得到的信息尽量封装到对象中(与此对应的规则中的信息也一样),这样子可以通过调用对象中的方法来比较,也很容易判断所有属性是否为空,能够更好地处理属性量较大的信息体。
第三步
回到 D34 套试题
核心:通过一份份试题,一步一步补充完整各种 target 所对应的 knowledge (即 PptCorrectEnums 中所写的东西),不断提高判题覆盖率。通过在 ApachePOIdemo 项目中进行不断的测试,即对想要取得的数据进行不断重复提取,以达到自己想要的效果。
ApachePOIdemo 是一个训练场。在这里,你可以进行无穷无尽地测试。其中已经包含了所有你可能需要知道的例子,所以在接手之前,你应该首先弄清楚这里所发生的一切,相信在后面的解析中,这会让你受益匪浅。
进入 ApachePOIdemo 项目
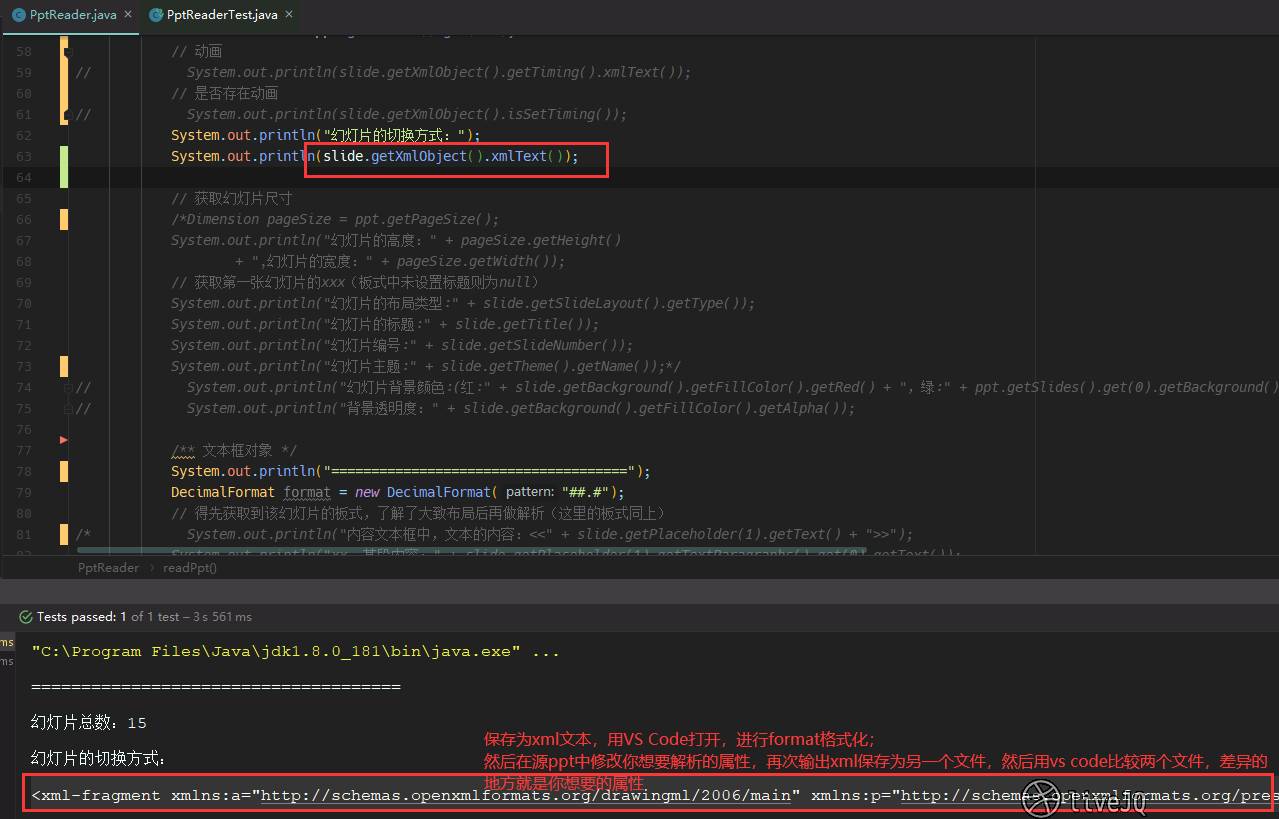
VS Code 需要先安装 XML Tools 插件才能格式化 xml 文档,快捷键是 Shift + Alt + f :
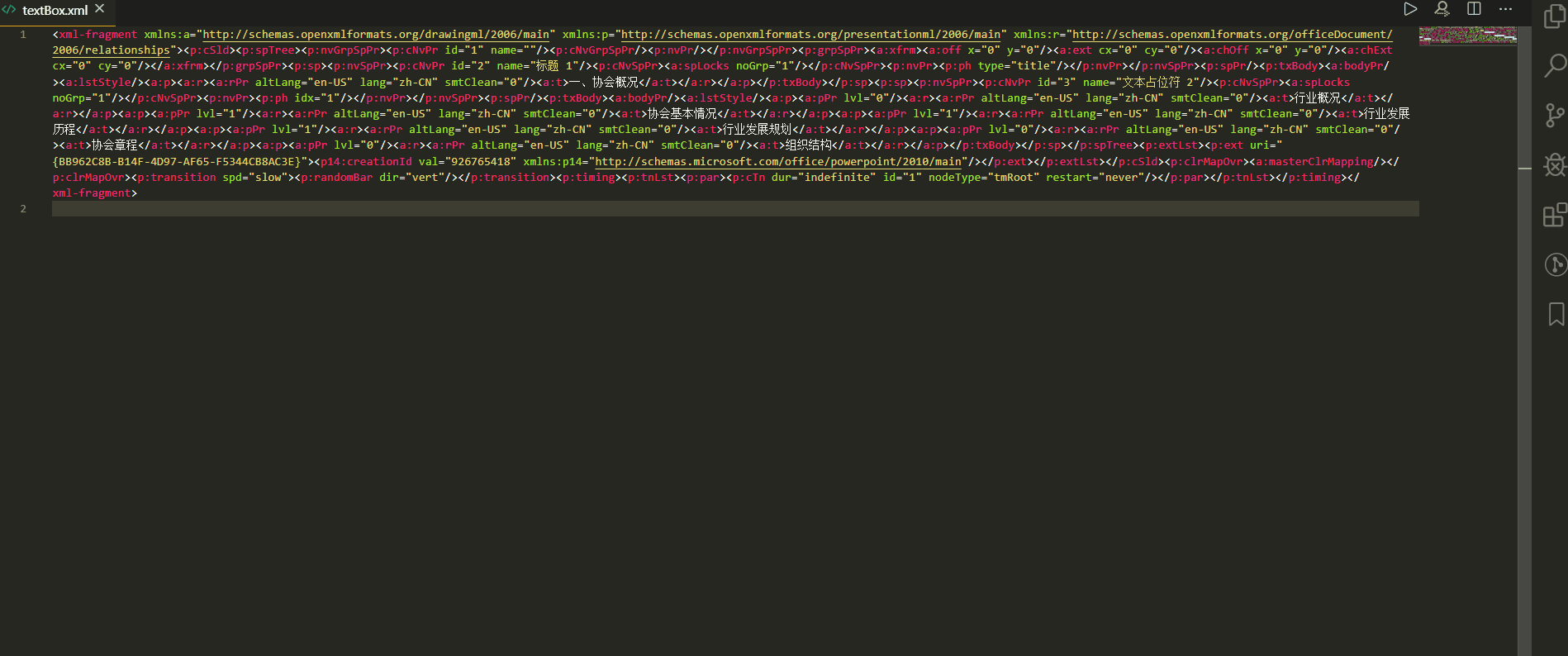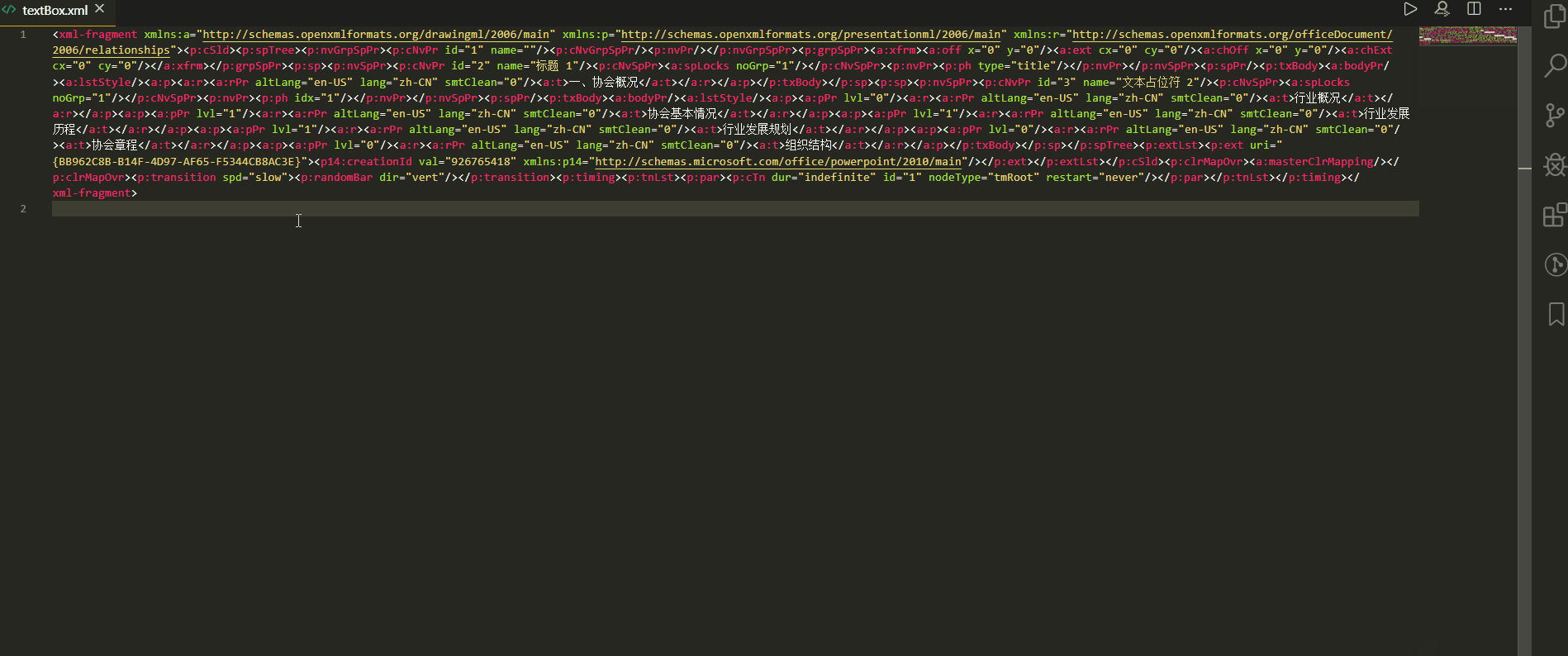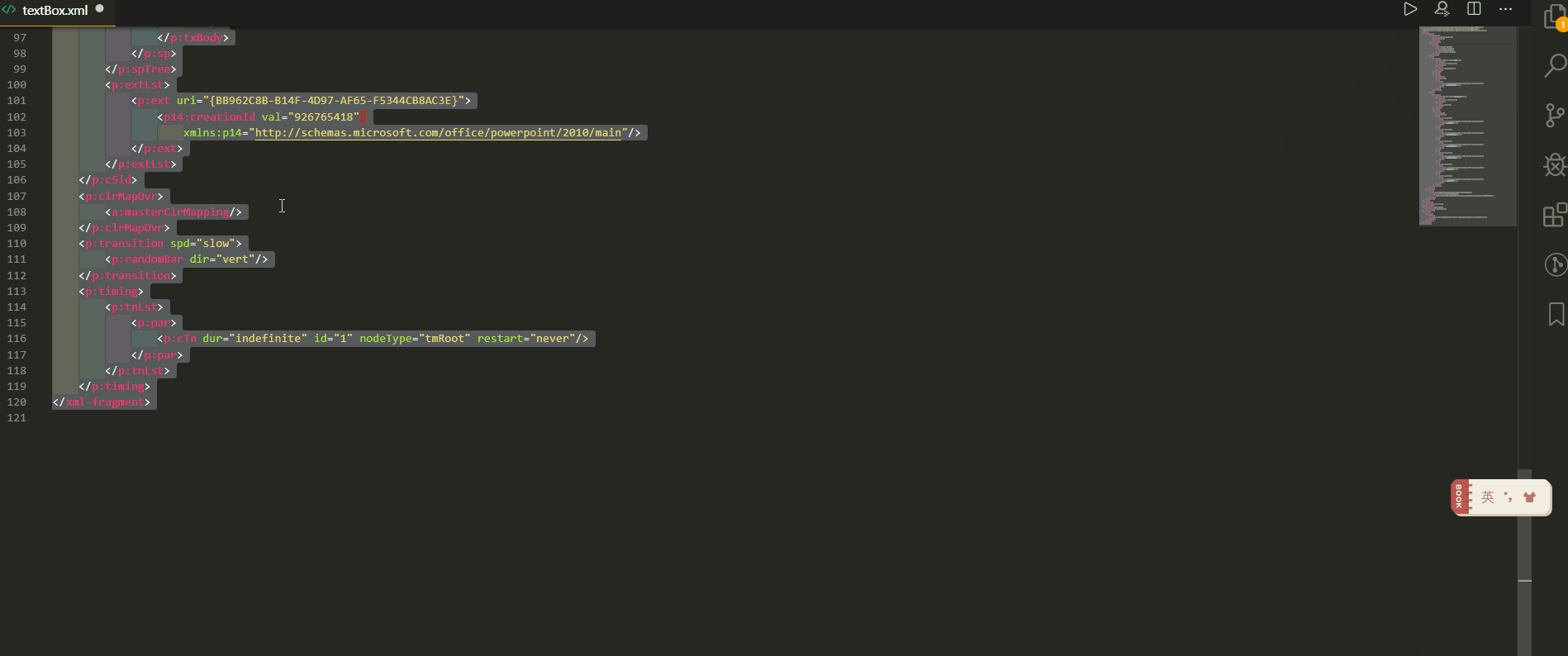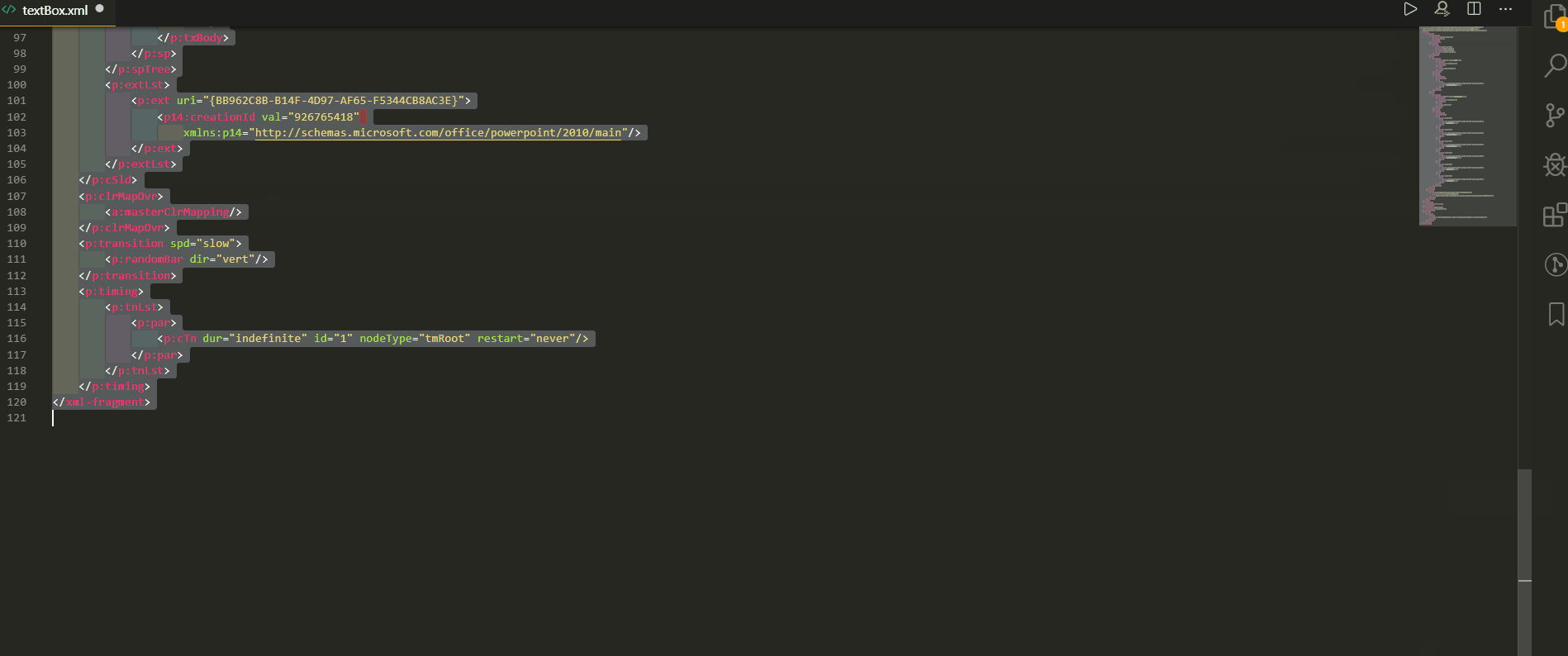
然后我复制一份,故意删除一行,来比较这两个文件,使用 VS Code可以很快发现他们之间的差异:
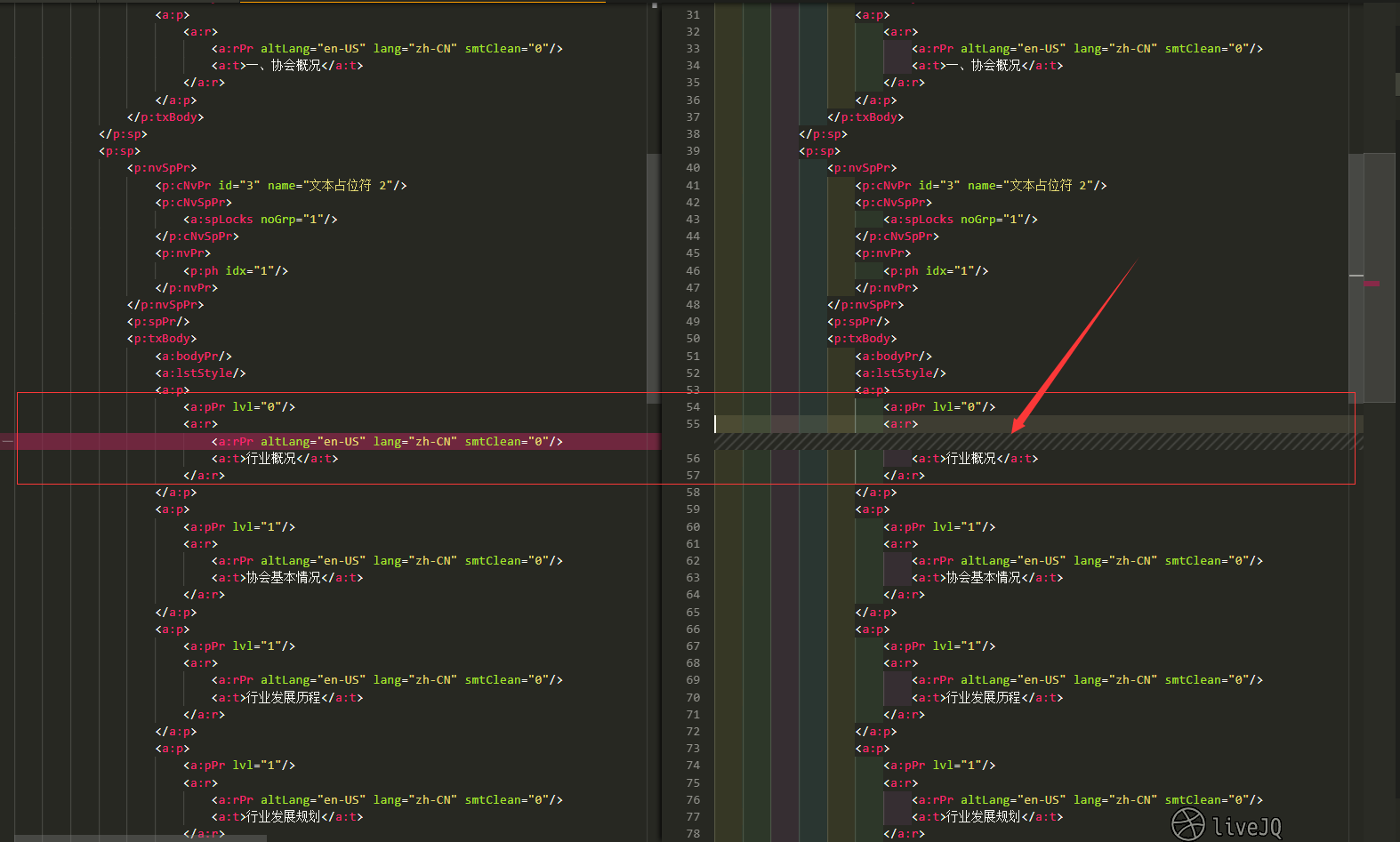
找到差异后就知道自己想要获取啥信息了,最方便的就是用 dom4j 工具,在加上强大的 XPath 技术就可以获取自己想要的属性了,说实话我也不是很会 🙂 。在此之前,indexOf 用过,直接get到 Node 信息也用过,都太繁琐,有好用的工具为啥不用嘞,我这叫自己找罪受....
index = 0;
num = 0;
child = "algn=\"ctr\"";
while ((index = xml.indexOf(child, index)) != -1) {
index = index + child.length();
num++;
}
h_align[1] += num;
上面代码可以用 Shift+Tab 键进行格式化
第四步
让工具投入使用
重构 PptCorrectServiceImpl,使 ppt 判题成为考试系统的一部分,去发挥它真正的作用 。
向着自动化方向发展

但是,当 target 和 knowledge 的覆盖率达到一定程度时,量变就会产生质的变化 。可以通过界面的方式,导入一份 PPT 文件(相当于标准答案),扫描并列出每张幻灯片中所包含哪些元素,每个元素旁边显示其所具有的属性,并且可以让我们去选择哪些属性需要匹配(include,默认值),哪些元素需要(exclude)等等这些需要人为调整的参数,最终生成 JSON 规则文件导出。

评论区